
Data Engineering - Genesis
Desde que se acuñó el término Big Data, van apareciendo diferentes roles a medida que va creciendo las necesidades y el ecosistema tecnológico. La ingeniería de datos o “Data Engineering” en inglés, es uno de los pilares en el diseño y desarrollo de flujo de datos que nos ayuda en la disponibilización del dato en el momento y la forma/formato más adecuado para que los usuarios o sistemas que lo requieran como entrada para iniciar su proceso. Por ejemplo el área de negocio, marketing, inteligencia de negocios (BI), los científicos de datos, analistas de datos, gerencia, entrada de otros sistemas automatizados como modelos de Machine Learning, Deep Learning, APIs, reportería, dashboards, etc. La imaginación pone los límites.
Semanas previas a escribir el presente artículo, tuve la oportunidad de ser invitado por la comunidad de Apache Spark México al Meetup Primeros pasos en ingeniería de datos con Apache Spark (pueden verlo por YouTube aquí) donde hablamos varios temas como la historia previa al Big Data, el nacimiento de Hadoop y Spark. Entonces decidí ampliar un poco más estos conceptos bases, orientado a todos aquellas personas que desean empezar o explorar el rol del ingeniero e ingeniera de datos, para simplificarlo estaré usando el término en inglés “Big Data Engineer”. ¡Entonces iniciamos el viaje!.
La necesidad de procesar datos
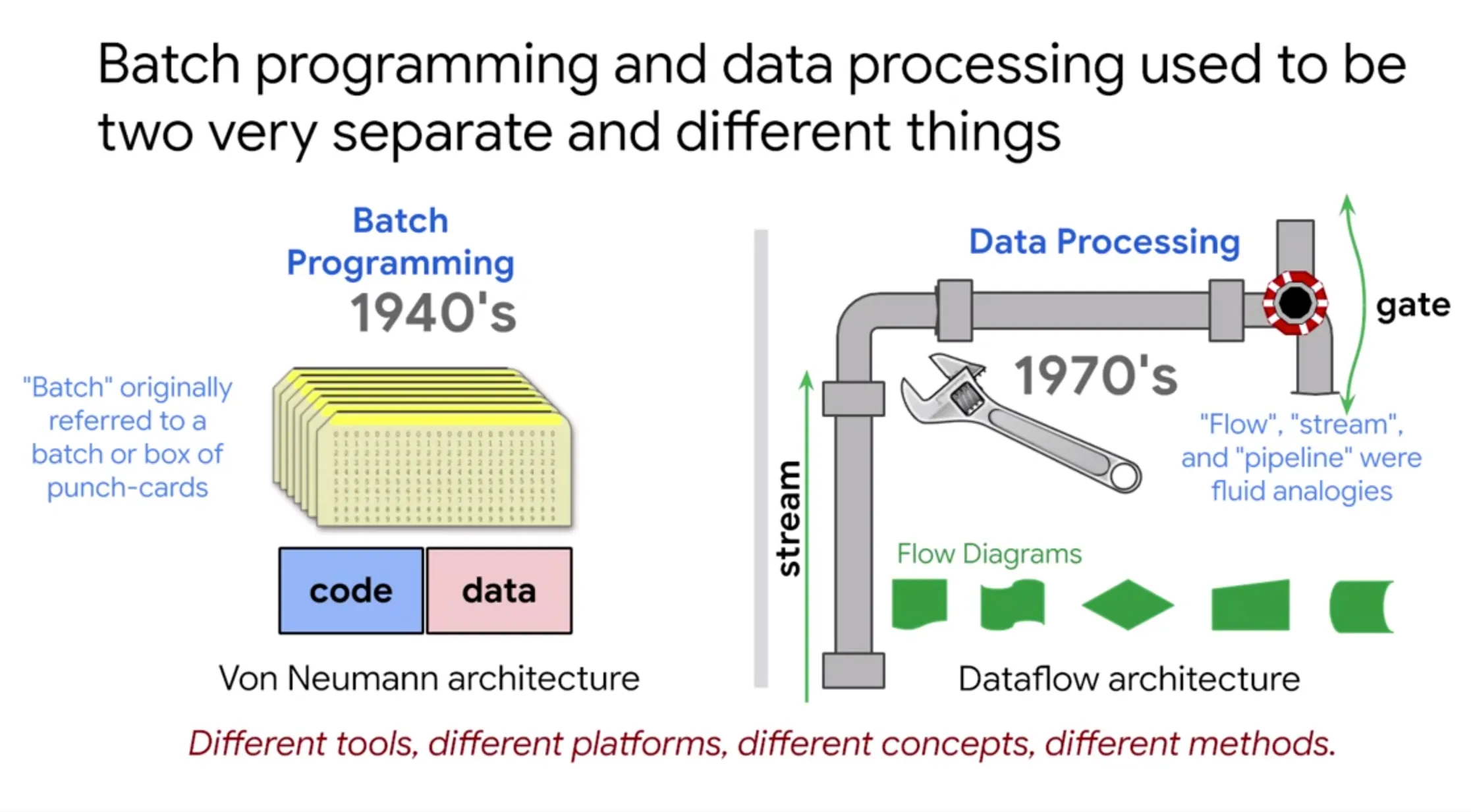 Fig 1
Fig 1
La necesidad de procesar datos automatizados se remonta desde la primera generación de computadores como el caso del ENIAC, allá por la década de los 40s. Cuando el almacenamiento de datos estaba en sus primeros pasos, estos se almacenaban en tarjetas perforadas en sistema binario y almacenados en grupos (“batch”) las cuales luego son procesadas para poder tener información automatizada (“informática”). Lo cual da origen a la programación en lotes o programación batch para su término en inglés.
Big Data el origen El término Big Data viene a ser un concepto más que una tecnología siendo este relativo según el espectador y el contexto temporal, por lo cual es algo complicado dale un año de nacimiento. En lo personal y concordando con varios autores podemos decir que todo empezó en Google, cuando la compañía del buscador se encontraba en sus primeros años de crecimiento, con muchos retos tecnológicos al igual que económicos, retos como:
¿Dónde y cómo almacenar el indexado de los sitios web? ¿Cómo procesar el gran volumen de datos indexados? Internamente trabajaron en tecnologías revolucionarias las cuales fueron expuestas para el público en general cuando Google publica los 3 principales paper que desencadenaron el ecosistema tecnológico del Big Data y de muchas tecnologías que usamos hoy en día de forma cotidiana.
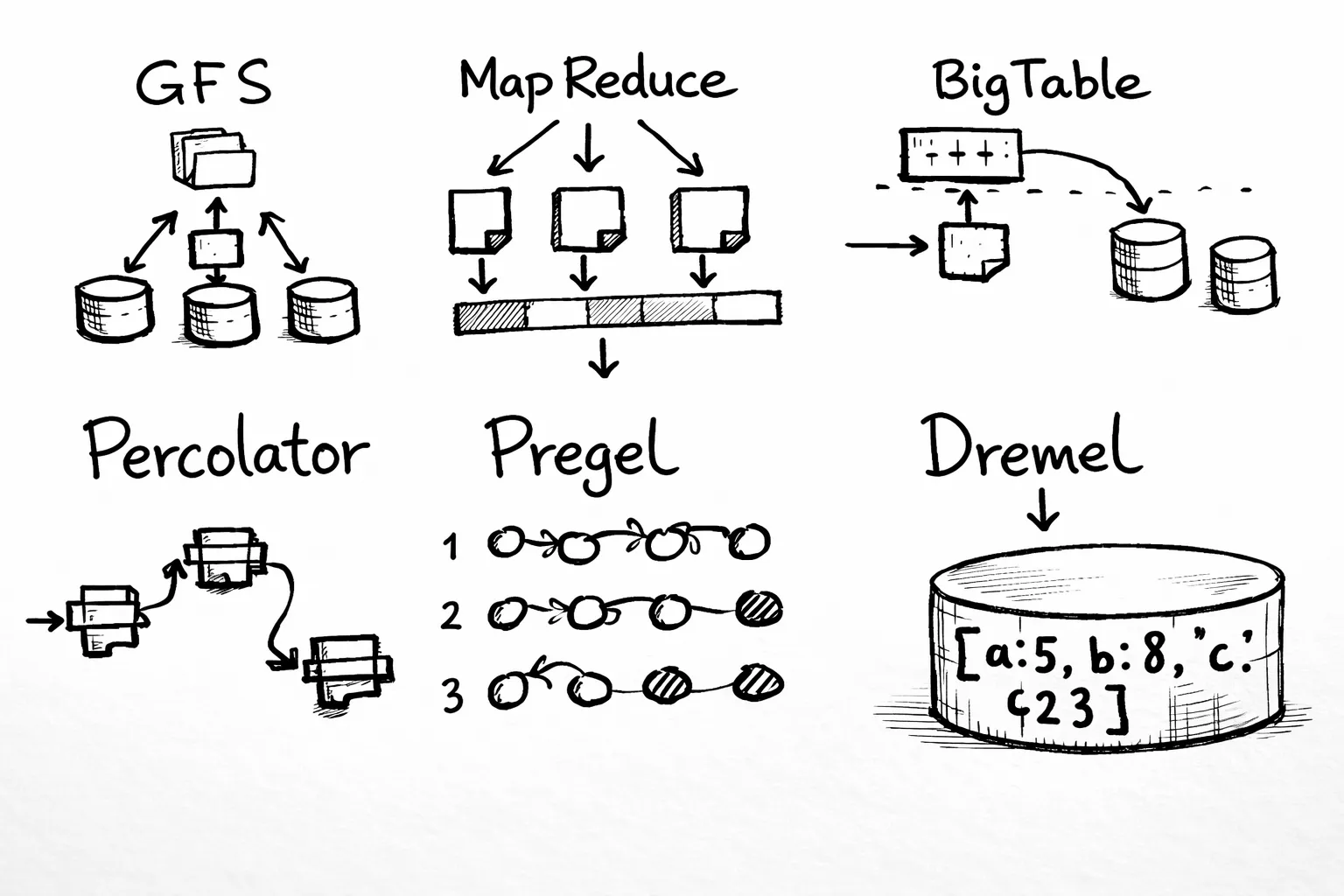 Fig 2. Big Data papers MapReduce, Google File System and Bigtable: the mother of all big data algorithms
Fig 2. Big Data papers MapReduce, Google File System and Bigtable: the mother of all big data algorithms
2003 Google File System(GFS) es el primer paper, “el origen del todo”. Básicamente GFS es un sistema de archivos distribuidos, los archivos se dividen en trozos “chunks” que se almacenan de forma redundante en un cluster de servidores económicos “cluster of commodity machines” .
Become a member 2004 MapReduce el referente de procesamiento distribuido para Big Data. usado previamente por google para calcular los índices de búsqueda.
2006 BigTable el paper que inspiró las base de datos NoSQL como Cassandra, Hbase, Dynamodb entre otras. Cassandra original de Facebook hace fuerte referencia a BigTable en el siguiente paper, al igual que Dynamodb de Amazon comenta sobre su influencia de GFS y BigTable en el siguiente enlace.
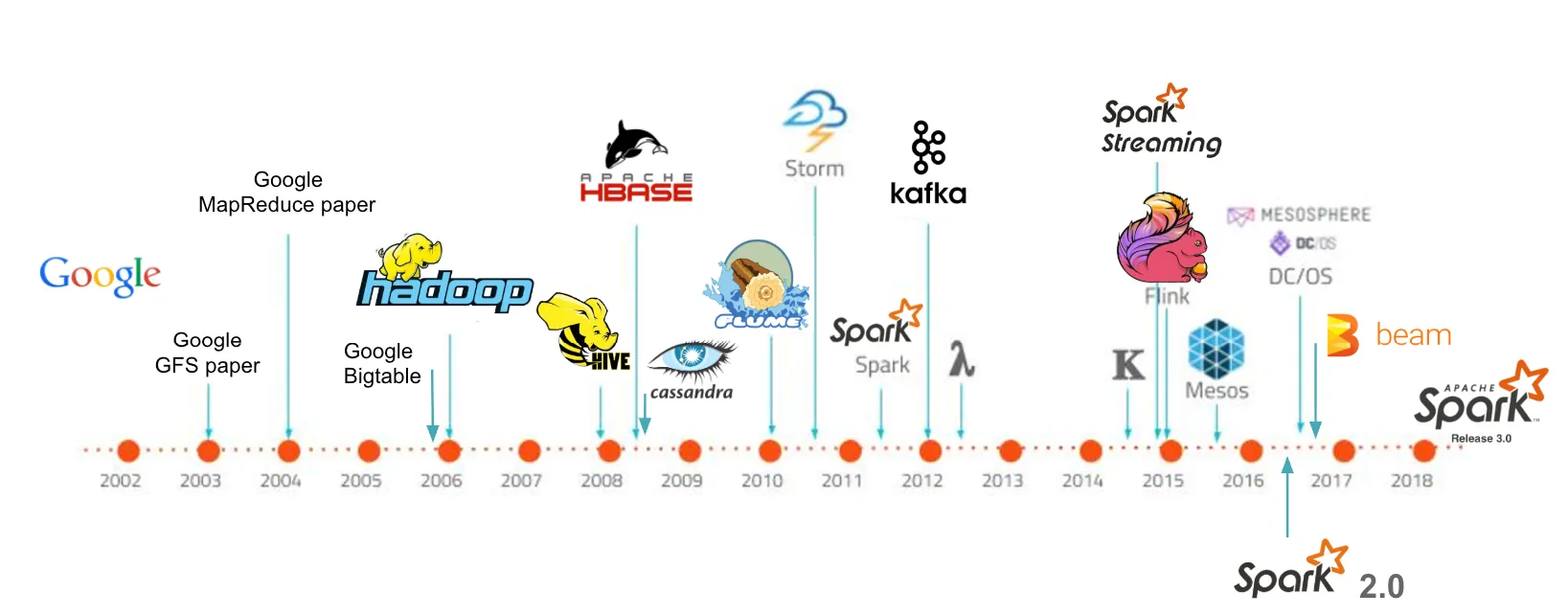 Fig 3. Big Data — línea temporal
Fig 3. Big Data — línea temporal
Hemos repasado un poco por la historia y los antecesores de las tecnologías modernas para Big Data.
Google juega un papel muy importante en el desarrollo e innovación tecnológico. A lo largo de los años como se aprecia en la Fig 3, han aparecido tecnologías que han marcado un antes y un después como el caso de Hadoop, Spark, Kafka y Kubernetes.
En el transcurso de los siguientes post, iremos explorando poco a poco sobre todo este ecosistema tecnológico y cómo dar nuestros primeros pasos en la ingeniería de datos.
¡Te veo en la siguiente historia!